I’ve been asked about getting audio of headwords into dictionaries a few times, so here’s a summary of how it can be done. The focus here is on getting individual audio files named as per the headword, so that they can be linked automatically in an online application.
Some of this is a recap in more detail of what I describe in an earlier article (2011).
Recording and inserting spoken headwords into a dictionary is not a trivial task, especially once the dictionary includes hundreds or several thousands of headwords. While the details of the method discussed here are likely to change as new tools emerge, it nevertheless illustrates the underlying principle of creating the data once and then allowing it to be used in multiple outputs.
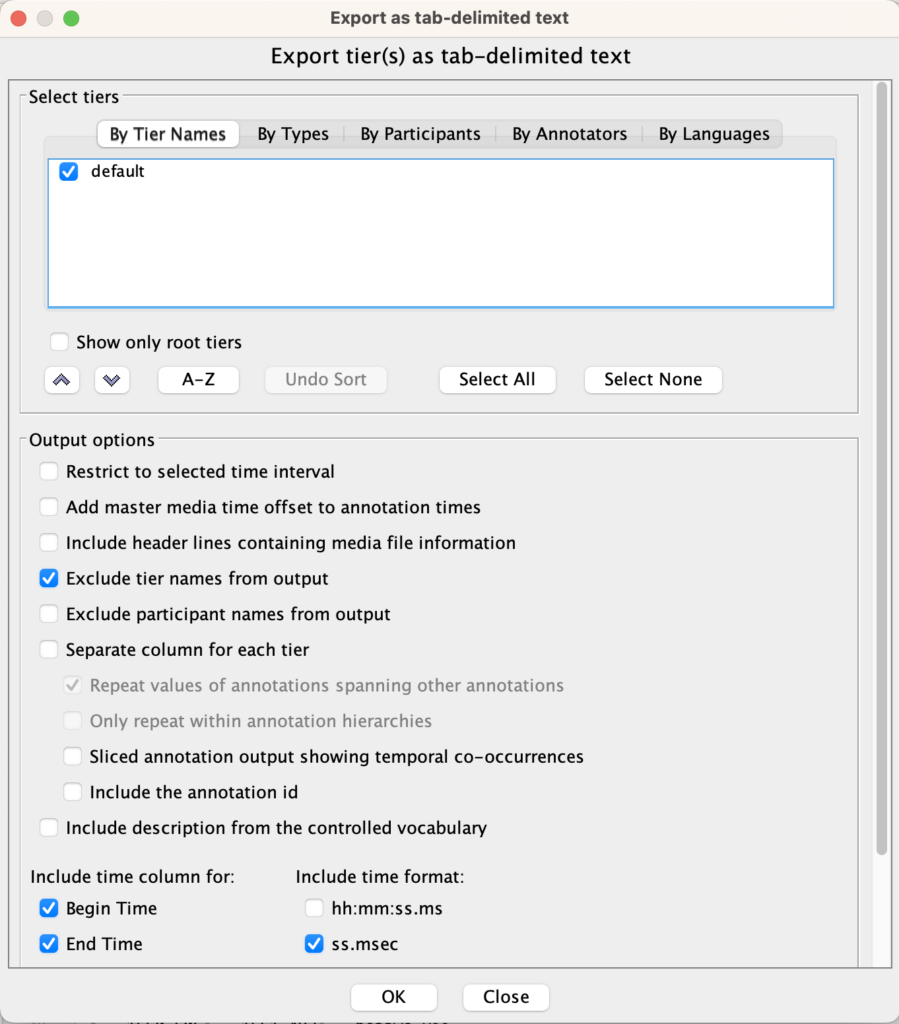
To begin, a list of headwords is extracted from the dictionary and prepared as a text file, printed and provided to a speaker as a script to read. Keep that script file as you will use it later to create a time-aligned audio file. In what is a fairly tedious process for them, speakers are then recorded reading the headwords, typically three times each to allow for varying intonation, but it could also be just once. These recordings are then time-aligned, first creating the fields for the words by using segmentation mode in Elan, moving quickly through the file to identify the start and end of words. Then, paste the script into the segments in Transcription mode so that each word is in the correct field or segment. This then results in a new Elan file of the text plus timecodes associated with the start and end of each headword. Using Elan’s ‘\Export\Export As\Tab Delimited text’ with the parameters in the image on the left exports a file that can be imported into software such as Audacity, which assigns labels to the audio file based on the timecodes, with each label named as per the headword.
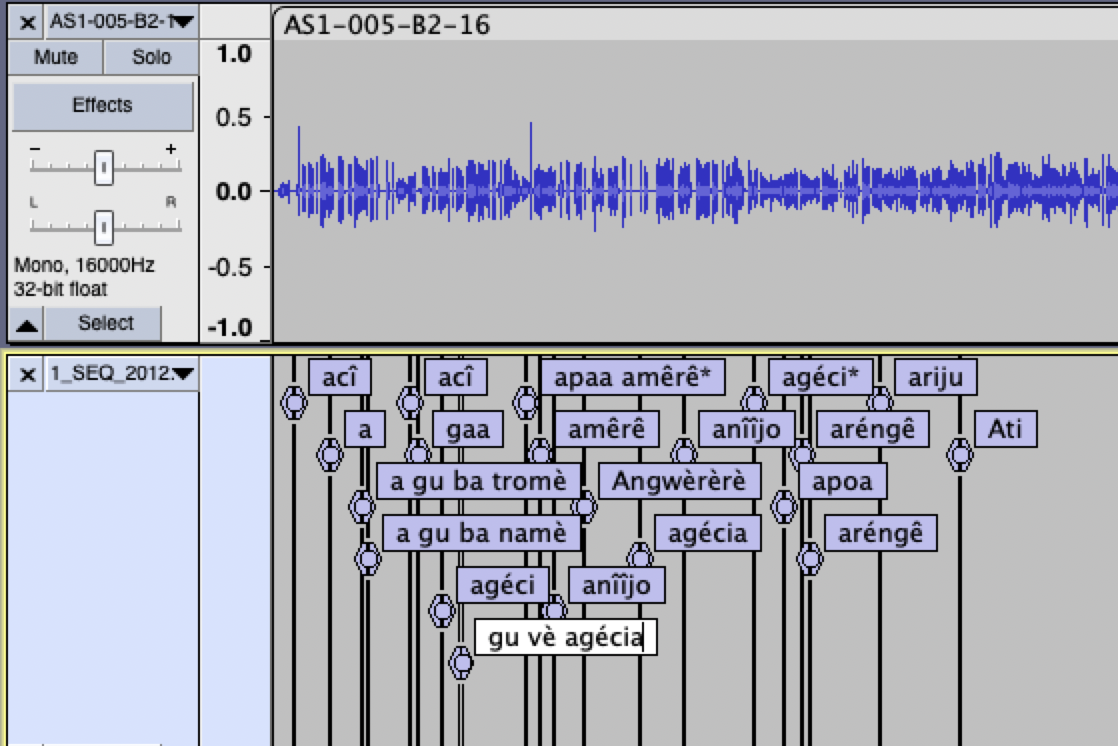
Once you have exported the file from Elan, open the audio file in Audacity, and choose ‘File\Import\labels’ and select the file you just exported from Elan. This should create an extra tier like this:
You now need to export those labeled areas as mp3 files, each named as per the label. To do this, select ‘File\Export\Export Multiple’ and use the following parameters (saving the output to a location on your computer).
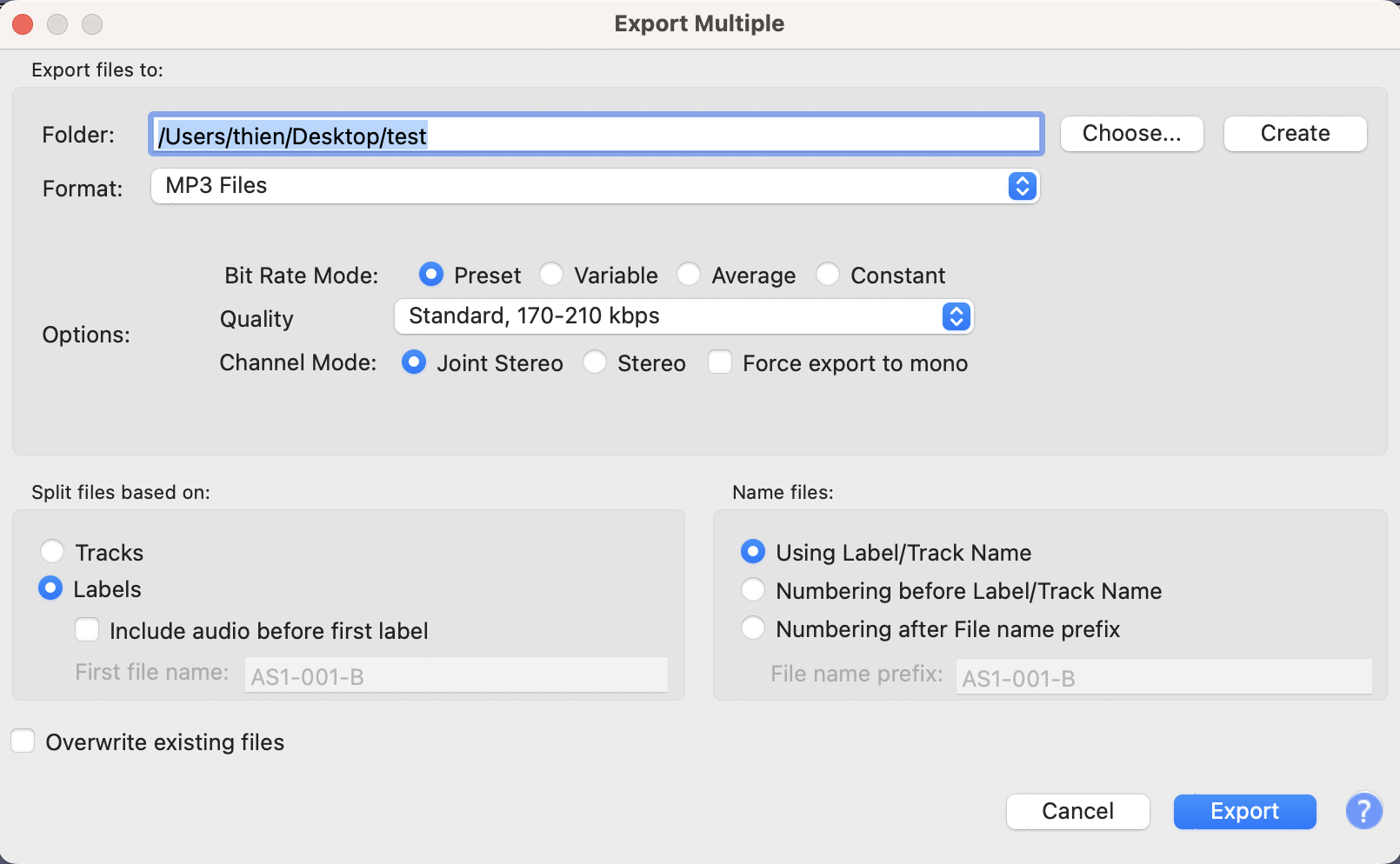
Audacity can then automatically segment the media file at these labels and creates individual files named by their labels, as many files as there are labels, so it is probably best to put them into a new folder on your hard disk. Putting these sounds into the dictionary is then a matter of coding in the delivery format, so, for example, each headword could be coded to call a file named as per the headword plus a media extension (perhaps .mp3). So, for the headword afsak ‘turtle’ we could create a tag in html that includes reference to a file named ‘afsak.mp3’, and do this automatically over the whole file of several thousand headwords.
Thieberger, Nicholas. 2011. Building a lexical database with multiple outputs: examples from legacy data and from multimodal fieldwork. International Journal of Lexicography, 24(3) 463-472;
 Follow
Follow
Here at Endangered Languages and Cultures, we fully welcome your opinion, questions and comments on any post, and all posts will have an active comments form. However if you have never commented before, your comment may take some time before it is approved. Subsequent comments from you should appear immediately.
We will not edit any comments unless asked to, or unless there have been html coding errors, broken links, or formatting errors. We still reserve the right to censor any comment that the administrators deem to be unnecessarily derogatory or offensive, libellous or unhelpful, and we have an active spam filter that may reject your comment if it contains too many links or otherwise fits the description of spam. If this happens erroneously, email the author of the post and let them know. And note that given the huge amount of spam that all WordPress blogs receive on a daily basis (hundreds) it is not possible to sift through them all and find the ham.
In addition to the above, we ask that you please observe the Gricean maxims:*Be relevant: That is, stay reasonably on topic.
*Be truthful: This goes without saying; don’t give us any nonsense.
*Be concise: Say as much as you need to without being unnecessarily long-winded.
*Be perspicuous: This last one needs no explanation.
We permit comments and trackbacks on our articles. Anyone may comment. Comments are subject to moderation, filtering, spell checking, editing, and removal without cause or justification.
All comments are reviewed by comment spamming software and by the site administrators and may be removed without cause at any time. All information provided is volunteered by you. Any website address provided in the URL will be linked to from your name, if you wish to include such information. We do not collect and save information provided when commenting such as email address and will not use this information except where indicated. This site and its representatives will not be held responsible for errors in any comment submissions.
Again, we repeat: We reserve all rights of refusal and deletion of any and all comments and trackbacks.