Following the previous blog post I had requests for more detail on how to convert a word-processor dictionary into the format needed to put the text into the software Fieldworks Language Explorer (FLEx). I’ll set out the steps below, but it does require some knowledge of regular expressions that I’ll explain as I go (you can also watch an intro to regular expressions here).
What FLEx needs to import is a text file that has the dictionary parts marked up with codes, like this, where \lx starts the headword, and \de starts the definition:
\lx alata’a
\de speak straight-faced and unsmiling
Subentries are marked with \se, and scientific names are marked by \sc.

First, you have to analyse the dictionary file to see if it is formatted consistently. Make sure you can see the tab, space, and carriage return marks in the document, by clicking on the icon in the header that looks like the one to the left here.
For example, lots of entries look this :

The structure here is a word at the line start, followed by a tab, followed by other text (the English definition), followed by a carriage return. So far, so good. But, other lines look like this:

Here we have indented lines, with two spaces before the text. This is used to indicate subentries to the main entry.
Another type of entry is as follows, where the definition extends beyond the end of the line and is wrapped, but with a tab to space it across to the right column:

In some entries this wrapping can go for several lines:

Scientific names are given in italics and in brackets:
‘ala’ala croton (Codiaeum)
‘alabusi type of tree (Acalypha)
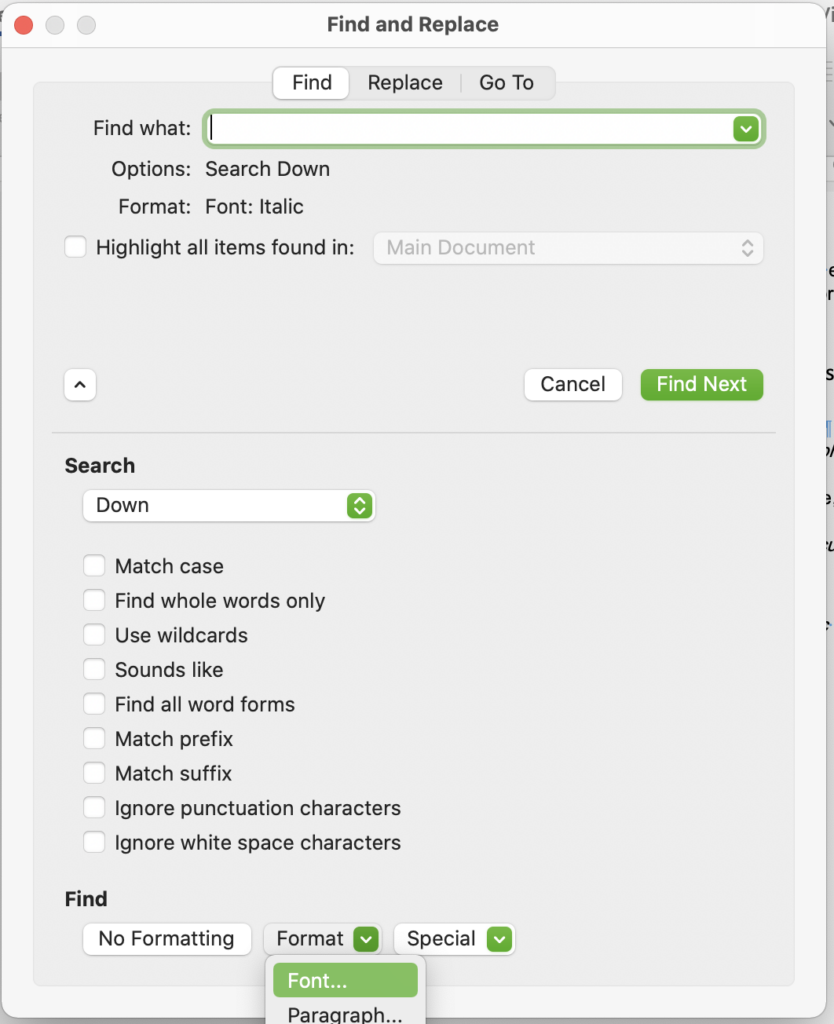
Because there is italic formatting here, we can find text with that formatting using MS Word’s Advanced Find and Replace function to then insert codes. Leave the search box empty, but select the font style italic. This will search for all italic text. You have to replace the text with \sc ^&. ^& means ‘put the thing I found here’, so it will put whatever text was in italics after \sc.

This is what it looks like after doing that change, with \sc inserted before an italic word. You need to take out the brackets around this, by finding “( \ ” and replacing with \, and finding “) ^p” and replacing with ^p.
Now, we need to find all carriage returns followed just by a tab, to find where the definition has gone longer than the end of the line. We will then replace that with a space.
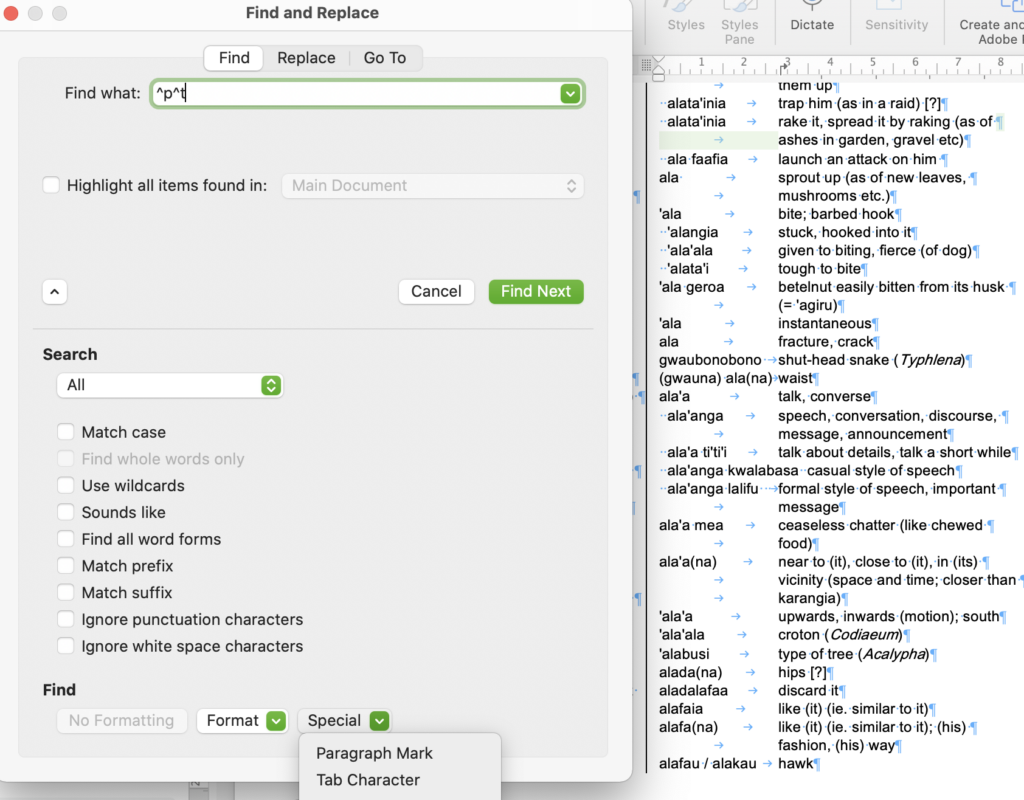
Again, using Advanced Find and Replace, you need to choose a paragraph mark from the special list at the bottom of the window. This will insert ^p into the search box. Similarly, now choose the tab character from the menu and it will put ^t into the search box. Put a single space into the replace box, and it will now replace all carriage returns followed by tabs to a single space. Do this as many times as it returns a result.
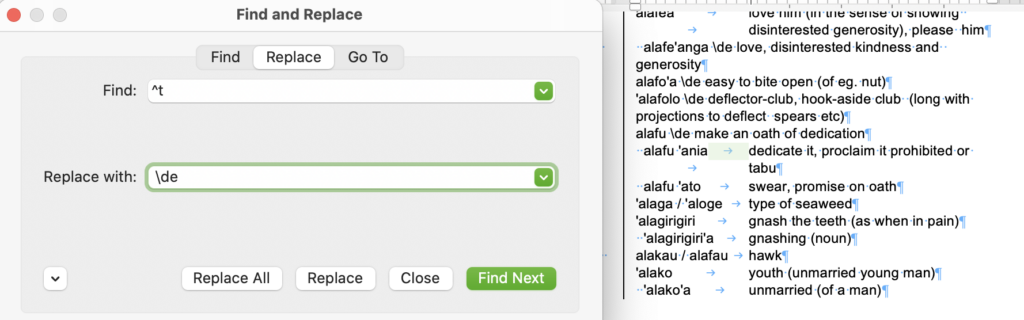
Now that we know all tabs only precede a definition, we can replace them with \de , and we do this the same way, by finding ^t and replacing with \de (with a space following it).
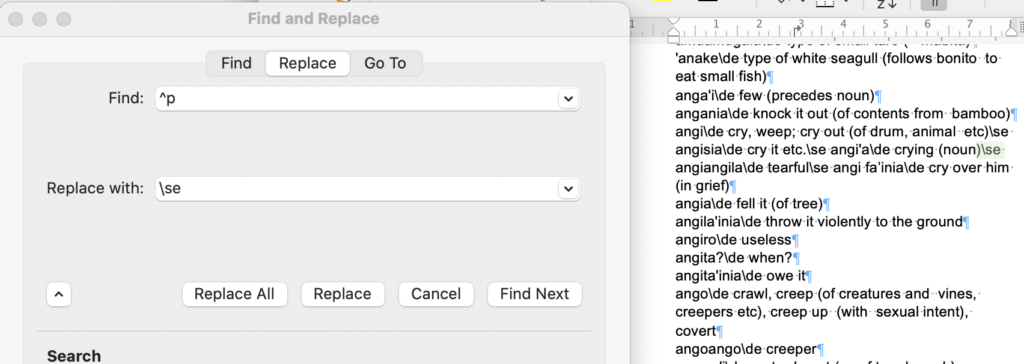
Next, we can identify subentries as having two spaces at the beginning of a line, so we can look for “^p ” (that is, ^p followed by two spaces), and replace it with “\se “
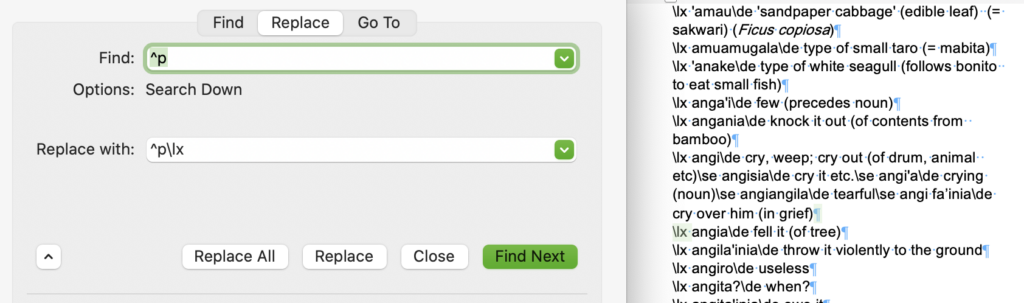
Now all remaining carriage returns occur before a headword, so can all be replaced by themselves with “\lx ” which is the marker for the headword.
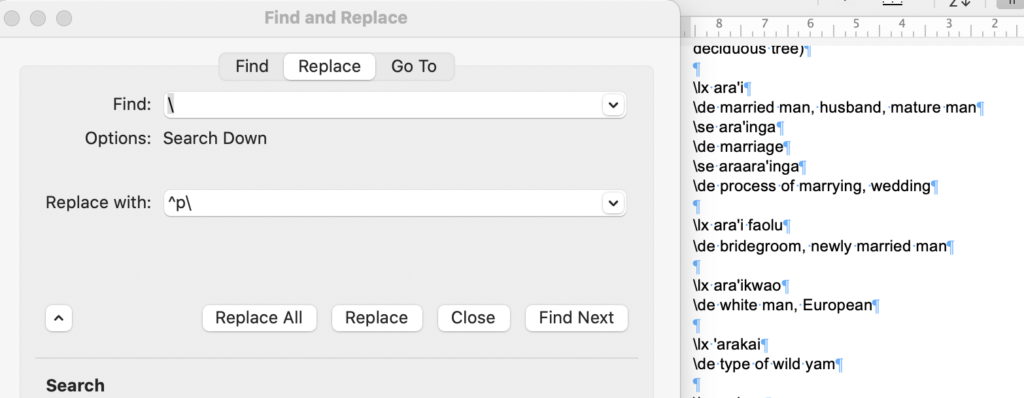
Last, you can put a carriage return before each backslash to create the format needed by FLEx. The last thing is to save this file as plain text.
You can now import that file into FLEx.
 Follow
Follow
Here at Endangered Languages and Cultures, we fully welcome your opinion, questions and comments on any post, and all posts will have an active comments form. However if you have never commented before, your comment may take some time before it is approved. Subsequent comments from you should appear immediately.
We will not edit any comments unless asked to, or unless there have been html coding errors, broken links, or formatting errors. We still reserve the right to censor any comment that the administrators deem to be unnecessarily derogatory or offensive, libellous or unhelpful, and we have an active spam filter that may reject your comment if it contains too many links or otherwise fits the description of spam. If this happens erroneously, email the author of the post and let them know. And note that given the huge amount of spam that all WordPress blogs receive on a daily basis (hundreds) it is not possible to sift through them all and find the ham.
In addition to the above, we ask that you please observe the Gricean maxims:*Be relevant: That is, stay reasonably on topic.
*Be truthful: This goes without saying; don’t give us any nonsense.
*Be concise: Say as much as you need to without being unnecessarily long-winded.
*Be perspicuous: This last one needs no explanation.
We permit comments and trackbacks on our articles. Anyone may comment. Comments are subject to moderation, filtering, spell checking, editing, and removal without cause or justification.
All comments are reviewed by comment spamming software and by the site administrators and may be removed without cause at any time. All information provided is volunteered by you. Any website address provided in the URL will be linked to from your name, if you wish to include such information. We do not collect and save information provided when commenting such as email address and will not use this information except where indicated. This site and its representatives will not be held responsible for errors in any comment submissions.
Again, we repeat: We reserve all rights of refusal and deletion of any and all comments and trackbacks.