Keeping track of what is recorded in the course of fieldwork is critical, both for your own future work and for longterm archiving. Recordings of dynamic performance (audio or video) are easy to misplace or misidentify and very difficult to locate once you forget what a file was named and what you recorded on a particular day. We ran a survey about how people record their metadata from January 21st to April 25th, 2016 and had 142 responses (see also the earlier blog post here). There were two multiple choice questions each allowing selection of more than one checkbox and the entry of free text responses. I can send the full results of the survey on request. This information will help inform the development of new tools for metadata entry. The responses are summarised below.
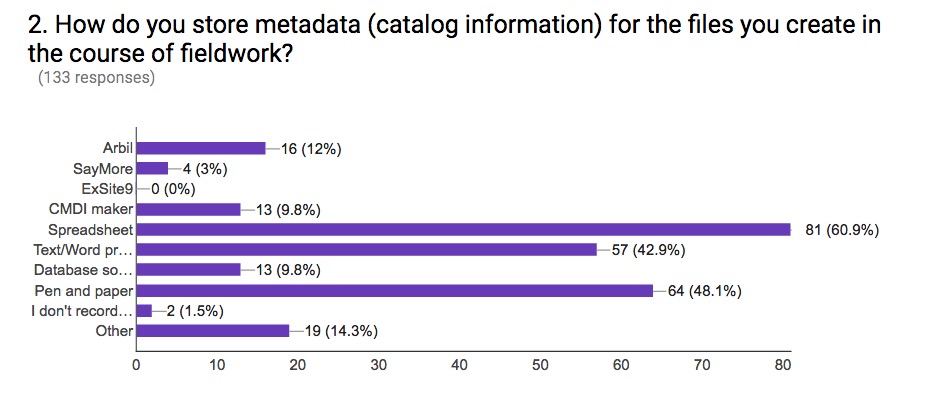
Question: How do you store metadata (catalog information) for the files you create in the course of fieldwork?
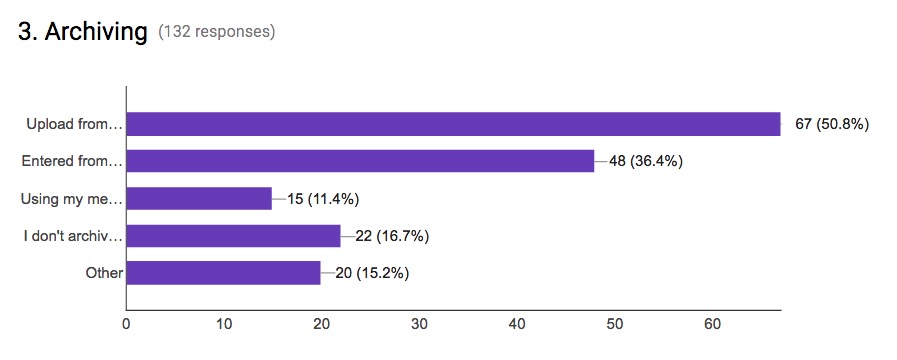
Question: How do you enter metadata for the archive you deposit with? (options were: Upload from metadata tool (as noted in the previous question); Entered from paper notes; Using my memory of the recording at the time of creating a record in the archive; I don’t archive my records; Other).
Summary of responses
Those filling in this survey are likely to be engaged in fieldwork (the entry screen excluded anyone who has not done fieldwork) and motivated to do better with their metadata entry. In general, very poor metadata creation is reported on (pen and paper, word processor files), or no metadata at all. A minority use dedicated metadata entry tools and, when they do, they complain about their complexity.
The type of tool used is determined by the archive targeted by the linguist, and by the researcher’s level of experience and comfort with the various options.
Some responses assumed it was only text files that required metadata (but did not address audio/video/images/etc)
Selected quotes
I am convinced in the value of metadata, but it still feels like an enormous time sink. I would love to see strategies for reducing the amount of time that needs to be spent on entering metadata.
Arbil is very bloated (SO many fields that are not really relevant to most). But I like the favourites feature, where you can save metadata about speakers, languages, etc and easily add them to new items. The local repository of stored data is another way to copy and paste info for new sessions that are similar to previous ones. Another added bonus- you can get the updated metadata from the published archive structure and bring it into your local repository, or bring new items into your favourites. This is especially helpful if you are collaborating with others and they have entered new speakers/languages, etc. You do not have to create all that from scratch. The down-side is that it is too verbose. Like Excite9, one should be able to define your chosen fields you want to fill in and keep that as a template.
I don’t archive my records, I ‘archive’ them on my own website.
One reported use of Evernote
Spreadsheets are simple but lack relational power
SayMore – useful for storing everything about a session/participant in one place and cross referencing the two. But I don’t like the lack of flexibility in metadata categories so really only use it for the basics
Ability to include images (photos) of legacy material in metadata
“Information is not linked to the data in any way” – seems to be asking for ability to look at/ hear primary material to assist in metadata dvelopment
Using a DBMS – prob of ‘no explicit links to data’ – maybe this mens no grabbing of metadat from the data and noability to see it in the metadata system
Pen and paper – quick, easy in the field, typed up later
Archiving?
A number of responses noted they used a mixed set of methods to note metadata. Some have it in several formats, and, as can be seen in the graph of responses, most use spreadsheets or pen and paper rather than a dedicated tool.
Question of how to deal with metadata that is not to be made public
“please help to create an intuitive user interface for a tool that has the capabilities of arbil :)”
“Arbil was necessary for archiving, but it’s incredibly painful to use. The best feature is that when I use it, the data is acceptable for the archive. The worst feature is that it’s time-consuming and frustrating to input metadata into it.”
This may be irrelevant for the purpose of this survey but I wish there was more of a discussion about the lack of transparency in viewable metadata for archives with searchable online databases. In PARADISEC and ELAR, there is a high degree of variability across depositors wrt how they list recordings of different communicative events ; in most cases it’s almost impossible to figure out the recording time for instance.
EXMARaLDA Corpus Manager, Custom Browser Interface, Oxygen XML Editor | For spreadsheets: Transform and then uploadSpreadsheets – Pro: efficient for large and simple (1:1 relations, “lists”) metadata sets; Con: not suitable for more complex data (n:m relations, iterative elements) / EXMARaLDA Corpus Manager: Pro: supports organisation of corpus workflow besides enabling metadata entry; Con: Less suitable for data transcribed in other formats / Custom Browser Interface: Pro: Optimised for one specific corpus workflow; possibility of errors minimized / Con: not transferrable to other scenarios / Oxygen XML Editor: Pro: Maximum flexibility; Con: licence fee, too scary for student assistants
 Follow
Follow
Here at Endangered Languages and Cultures, we fully welcome your opinion, questions and comments on any post, and all posts will have an active comments form. However if you have never commented before, your comment may take some time before it is approved. Subsequent comments from you should appear immediately.
We will not edit any comments unless asked to, or unless there have been html coding errors, broken links, or formatting errors. We still reserve the right to censor any comment that the administrators deem to be unnecessarily derogatory or offensive, libellous or unhelpful, and we have an active spam filter that may reject your comment if it contains too many links or otherwise fits the description of spam. If this happens erroneously, email the author of the post and let them know. And note that given the huge amount of spam that all WordPress blogs receive on a daily basis (hundreds) it is not possible to sift through them all and find the ham.
In addition to the above, we ask that you please observe the Gricean maxims:*Be relevant: That is, stay reasonably on topic.
*Be truthful: This goes without saying; don’t give us any nonsense.
*Be concise: Say as much as you need to without being unnecessarily long-winded.
*Be perspicuous: This last one needs no explanation.
We permit comments and trackbacks on our articles. Anyone may comment. Comments are subject to moderation, filtering, spell checking, editing, and removal without cause or justification.
All comments are reviewed by comment spamming software and by the site administrators and may be removed without cause at any time. All information provided is volunteered by you. Any website address provided in the URL will be linked to from your name, if you wish to include such information. We do not collect and save information provided when commenting such as email address and will not use this information except where indicated. This site and its representatives will not be held responsible for errors in any comment submissions.
Again, we repeat: We reserve all rights of refusal and deletion of any and all comments and trackbacks.