Every time I revisited my fieldsite I was asked for copies of photos or recordings and I wanted some way that these could be accessed without me having to be present. When I started visiting Erakor village in central Vanuatu there was intermittent electricity available, usually only in the evenings in the house I lived in.
CD players were common enough, so I was able to make audio CDs with tracks made up of various villagers telling stories or singing songs, or the choir singing hymns. These and the liner notes came out fairly readily from my text/media corpus, so that creating the template CD took about 2 hours and then burning multiple copies was a simple matter.
Over the years the electricity supply has become more reliable, and the school was given a set of ten computers by their sister school in Australia. Having heard about Linda Barwick’s experience in establishing an ITunes installation at Wadeye (see Barwick and Thieberger 2006, and also Linda’s method for getting audio files into publishable form in this blog item ) I decided to do the same thing at Erakor school.

Erakor school in 2008
The same tracks that went onto the CD then were added into ITunes, with names that gave an idea of the contents, and the ‘Artist’ name being the speaker or performer. It is then possible for users to create playlists of their favorite set of stories or songs and to burn them to a CD.

Here’s a picture of Endis Kalsarap constructing a playlist on the school computer.
In order to get the stories into a format that allowed them to be located in the archival file and then segmented into mp3 versions for ITunes I had to have indexed the media files. I did this using software like Transcriber or Elan, and have kept the filenames constant over time so that everything was still locatable, now over a decade since my first recordings were made. I stored these indexed files in a media corpus (in my case in Audiamus) and so could retrieve the start and end time of any text from that corpus. I then used that information to locate the same stretch of media using Audacity, cut the selected piece out as an mp3 file, named uniquely describing the contents (e.g., person name – topic, ‘Kalsarap-Malakula English Police’, ‘Tokelau-Ati Kal go Apu Nar’, ‘Hymn 114 Natus Nalag’). These were then ready to import to ITunes, as you can see in the next image.
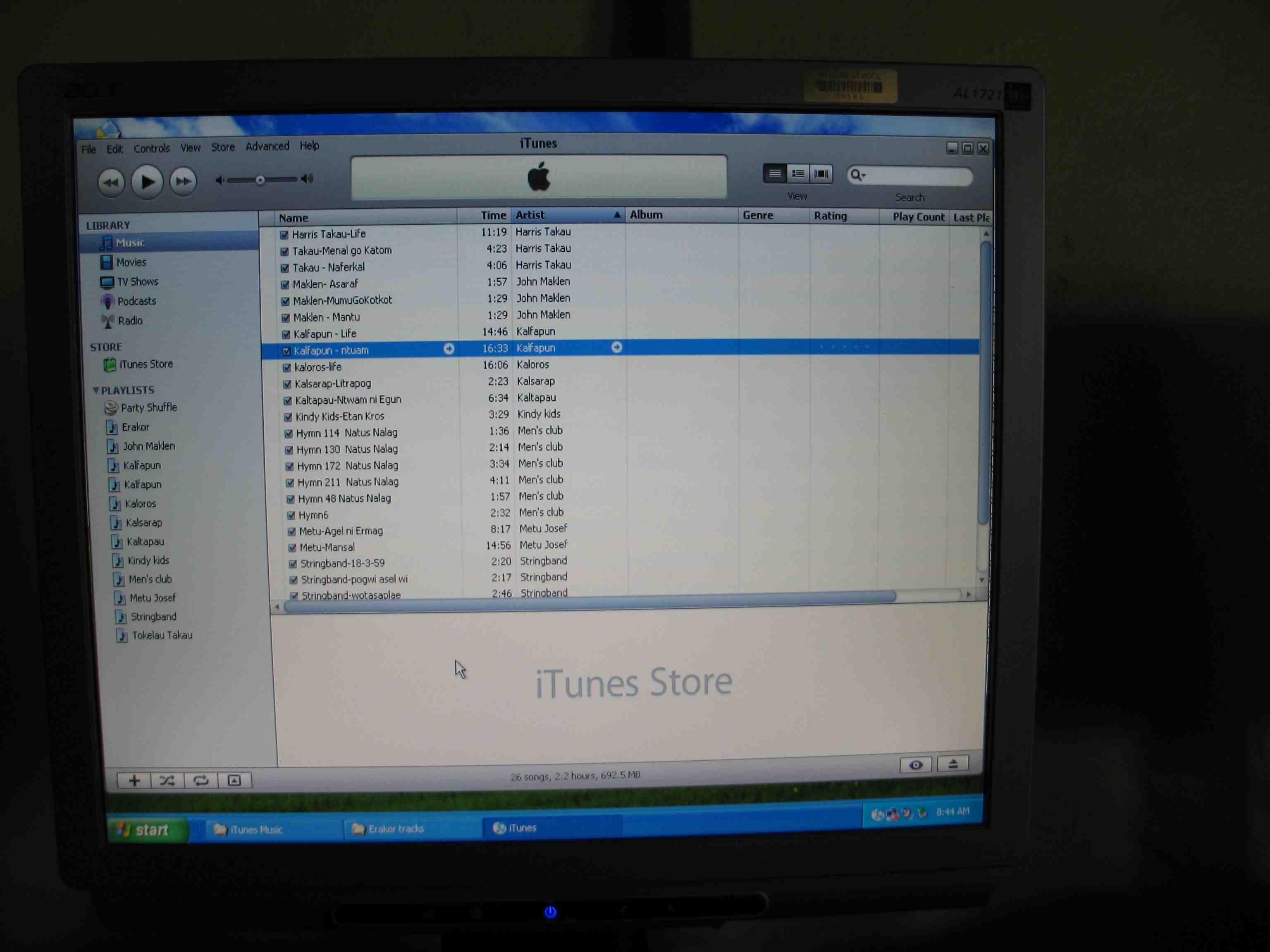
I am convinced by this and other examples that it was worth putting in the time to creating a reusable media corpus of my field recordings, indexed by textual transcripts. The basic principle is creating the data once, and then using it many times in many different ways.
Barwick, Linda and Nicholas Thieberger 2006, Cybraries in paradise: New technologies and ethnographic repositories. C. Kapitzke & B. C. Bruce, (Eds). (2006). Libr@ries: Changing information space and practice. Mahwah, NJ: Lawrence Erlbaum. 133-149. (http://repository.unimelb.edu.au/10187/1672)
 Follow
Follow
Thanks Nick – this is the kind of encouraging reading field-workers need..
Nick,
Nawesien nen itrau wi pe wi, nafet ntaewen me nawesien teflanen kin tumur na tukleka ruk tegmraak egmrom society gakit, ntaewen gakit me tu weswes plake skot technology teflan kin tukfo tae leka na kefo tae welu kit nanre ni nafsan me ntafnauwen ni nafsan gakit! Psawi ki mus Linda nawesien kpur nen ra pregir ruen.
My (rough) translation of Joel’s comment (with his permission): “This is really great, this is the kind of knowledge and work that we would like to see supporting our society and our knowledge and we can work with technology like this so that it can help us with language and teaching our language! Thanks to you and Linda for the big work which you have set up.”
[An interesting note that the term ‘tegmraak’meaning ‘to set up or erect or establish’ used above does not (yet!) appear in any of the texts or the dictionary of South Efate, so the blog now becomes part of the corpus].