The problem: you have text files and audio files, but the text files are not aligned to the audio files.
I imagine there are a few readers out there who have transcriptions of audio files that never made it past an utterance per line text file. This is a post for you, if you’d like to know how to import and time-align those files in ELAN.
[Edit: thanks to Anggarrgoon and Honestpuck for their suggestions and improvements]
ELAN allows you to import tabbed text, with or without time codes included. The process is described in the manual.
To get it to work you need to convert your text transcript into a “tabbed text” file. This means that there will be at least two columns of text, separated by tabs.
For instance, here is an example transcript:
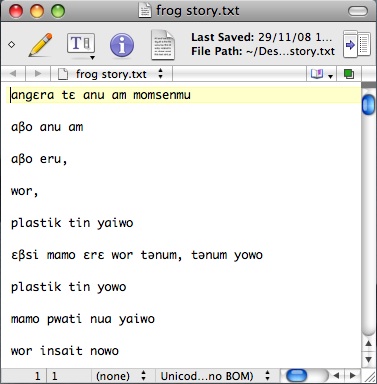
I need to remove the blank line between utterances and then I have to add, for instance, the name of the new tier and a tab to the beginning of every line. To do this I’m going to use the find and replace function in TextWrangler, a free (Mac only sorry) text editor that supports regular expressions.
Using find and replace with regular expressions enabled (check “Use Grep” in TextWrangler) to remove the blank line, I replace “\r\r” with “\r”, and then to add a new column with the name of the ELAN tier in it, I replace “^” with “Monica\t”. “\r” is a “metacharacter” meaning a return character. For some types of text you may have to use a newline character (“\n”) or a combination (“\r\n”). “^” is a metacharacter meaning the beginning of a line, and “\t” is a metacharacter for a tab. See the link above for more information on regular expressions, and see the references at the bottom of that page for gentler introductions to regular expressions.
The end result should look like this (where “Monica” is the name of the tier that I’m importing text into):
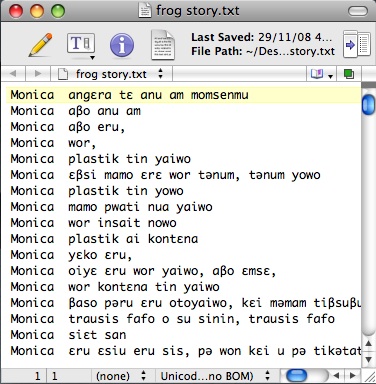
Now the text file is ready for importing into ELAN. But before we do that, we need to do a little maths. When there is no time code data, ELAN imports the text with a standard duration for each utterance. If you stick with the defaults, I think you’ll find that it’s a pain in the neck aligning the text with the audio. You can vary the duration however. [Edit: IMPORTANT see note below. Thanks to Anggarrgoon for a much better method!]
The problem is that ELAN has no idea where your transcript begins and ends, and so it simply adds the utterances to the beginning of the file. It also gives them a quite short duration by default. Assuming that the length of utterances that you’ve transcribed do not vary wildly, or that there are long periods of silence, then the best length will be the length of the transcribed portion of your audio divided by the number of utterances.
Use ELAN, or an audio editor like Audacity to figure out the length of the transcribed portion of your audio file in milliseconds, and divide it by the number of lines in your transcript. [edit: Don’t forget to round down. Rounding up may result in you loosing some annotations if they fall outside the time span of the recording – Thanks Tony!].If you move the cursor to the last line in TextWrangler, the line number is in the bottom left hand corner.
Choose “File” -> “Import” -> “CSV/Tab delimited text file”, locate your text file, specify Tier for the column with the tier name, and annotation for the column with the utterances in it. The audio portion for which I have transcribed text is 551930 milliseconds long, and I have 168 utterances in that period. So I will set the the Default annotation duration to 3285:
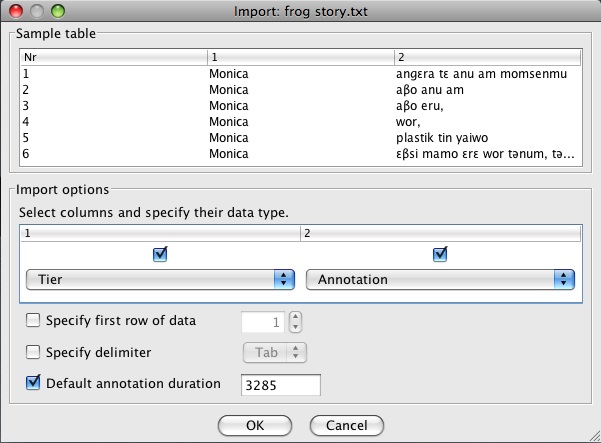
After clicking “OK” a new ELAN document will pop up. You need to add your audio file by going to “Edit” -> “Linked files…”. Add your audio (and/or video files) and click “Apply” and then “Cancel” (to close the window).
Then you should shift all the annotations to the beginning of the transcribed portion (just so you don’t have to scroll backwards and forwards a lot as you properly align the annotations), by going to “Annotation” -> “Shift All Annotations”. For me, that is 53000 milliseconds into the recording (after I’ve done my standard introduction).
To re-align an existing annotation, you need to have the annotation selected by first clicking on it. This will select it and a portion of the audio, and the black underline marking the span of the annotation will change to blue:
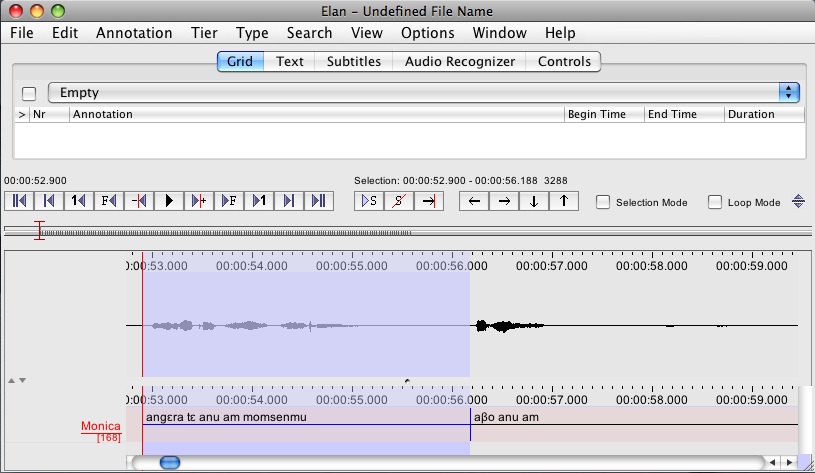
Then you need to select the region of the audio that corresponds to your selected annotation. In my example, they’re conveniently located very close together:
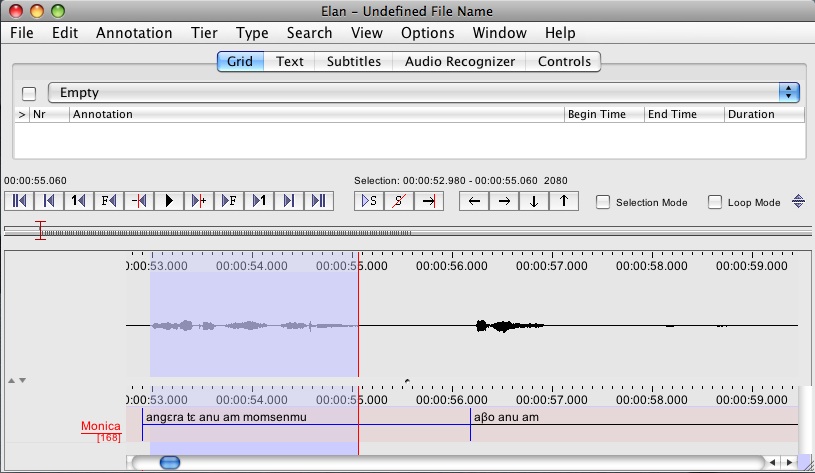
You can play back your selection to check that it’s right by typing the key combination shift-space, or clicking on the play button with an “S” on it. You can extend the selection (if there are two “chunks” of audio to one annotation) or reduce it (if you’ve selected too much) by holding down shift and clicking on the new boundary of the selection.
When you’re happy that the audio and text align, type command-return (on a mac) or control-enter (on a PC) (See also the ELAN Manual). You should see the bounds of the annotation (the blue line) shift to your selection:
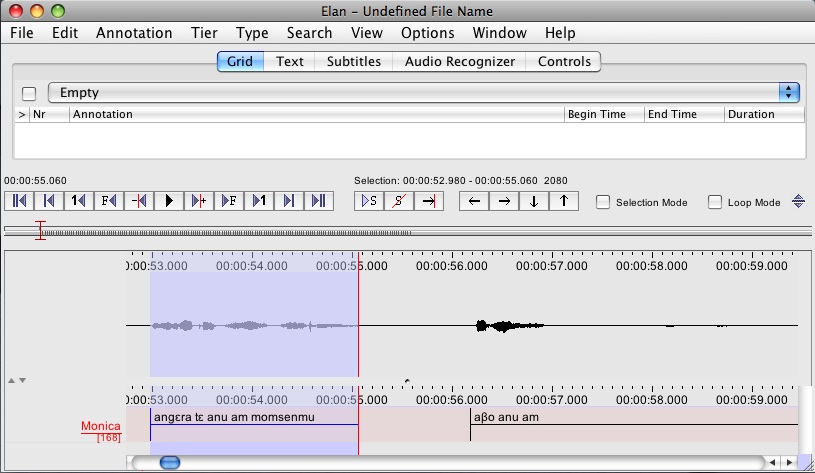
So, lather, rinse, repeat for each annotation and you should have a nicely time-aligned file. Oh, and don’t forget to save!
NOTE: One complication you may run into is that if for instance the annotation you are aligning is quite far from the point in the audio you wish to align it to, then the annotations may move out of order. There is no easy fix to this situation. You may find it easier working from the end of the transcript to the beginning. You may find it easier to first shift those annotations that are closer to their audio counterparts, or you may find it easier to cut and paste annotations into a new tier, so that the process of aligning them doesn’t shift unaligned annotations elsewhere. Please let me know if you can think of better ways to do this.
Edit:
Thanks to Anggarrgoon for pointing out a much simpler method to align annotations with corresponding audio chunks!
First of all, ignore my suggestion to extend the duration for imported annotations, a short duration will be ok in this new method.
Second, turn on “Bulldozer mode” under the “Options Menu” -> “Propagate Time Changes”. This will shift your annotations rather than reorder them. However, you must begin from the beginning.
 Follow
Follow
Thanks Tom,
Transcribe always annoyed me, so I generally typed out my transcriptions into word documents and interlinearised them myself – no wonder I never finished.
A note for any linux users, Gedit (Gnome’s built-in text editor) doesn’t come with regular expression support, but it can be downloaded as a plugin from here (tar.gz), but it takes a bit of know-how to install. I think it involves unpacking the archive into ~/.gnome2/plugins and then enabling it in Gedit’s preferences. Once enabled though, it’s very useful, and supports back-references (like \1, \2 etc.).
I remember there being some text editors available for Windows that supported regular expressions, but by memory they were all commercial and would only work for free for thirty days or so.
There are heaps of good text editors out there that support regular expressions. One that is cross platform, free and supports regular expressions is JEdit. The trick is to look for a programmer’s text editor. They are often packed with features and are also often open source.
Another handy feature that many programmer’s text editors offer (JEdit and TextWrangler included) is the ability to search and replace across multiple files.
Tom,
For people who don’t use the Mac, or who like the command line then :-
awk -F \t ‘ $1 { print “Monica\t”$1 }’ “frog story.txt” > frog.tab
in the same directory as your file will do the same as your TextWrangler commands. Of course Windows users would require Cygwin or some similar utility installed to gain access to Awk.
Oh, and the systems programmer in me would follow your advice and start at the end of the transcriptions and work backwards with the one small touch that I’d round the default annotation down to 3000 or 3100 milliseconds to make it much more likely that I was always moving the time scale into clear space.
Thanks Tony,
Very true about the rounding down. ELAN will indeed truncate any annotations outside the time span of the audio.
Tom, Bulldozer mode automatically shifts following annotation. The way I do this is to import the file with the annotation length at about 2 seconds (with no space between them, but it doesn’t matter), and I start from the beginning of the file (you have to in bulldozer mode). Say the time for annotation 2 goes from 5-8 secs. Once annotation 2 is moved into place, annotations 3ff will also be moved and will start at 8secs. Then if you move annotation 3 to 10-12 seconds, annotations 4ff will now begin from 12 secs. It’s *much* easier than doing it by hand in regular mode.
Thanks Claire, I’ve incorporated that into the article. That is indeed a great improvement on my suggested method. I’m glad I didn’t write to the ELAN developers suggesting a “shift” mode now… can’t believe I missed that one.
Just came across this – thanks Tom. Have been soliciting advice on how to do this for years as most of my texts are in Toolbox and linked by line numbers to sound files in SoundStudio. The most recent discussion I had – with an Elan person at MPI – resulted in them convincing me there wasn’t much point getting already interlinearized and time-aligned texts into elan. In retrospect I think some elan developers don’t actually realise how useful the program is for linguists! Will definitely make another attempt with your method.